通过Magenta.js的RNN来生成web音乐。
Recurrent Neural Networks(RNN)是一种考虑时间维度的神经网络训练方法。一般的神经网络,在输入映射到输出的过程关系,不会考虑输入的顺序。例如识别图像中的对象,就是这样的一个情况,因为每个case都是独立的事件。但是在有一些的 情况下,输入的顺序是重要的特征之一,例如机器翻译,单词的顺序很重要,所以一般的神经网络表现不理想。
在本篇中,我们考虑通过LSTM考虑特定的事件顺序。然后探索Magenta.js的DrumRNN应用,生成不同的序列鼓声。
Step 1:理解神经网络和循环神经网络
我们可以把神经网络看成是函数迫近器,如果神经网络足够复杂,可以用它来定义任何的函数。所以神经网络最简单的形式就是理解为感知器。它由以下几个部分组成:
- Input:神经网络的输入内容
- Weights:为每个输入的内容分配权重
- Bias:添加到输入内容的常数
- Actication function:输入和输出的映射关系
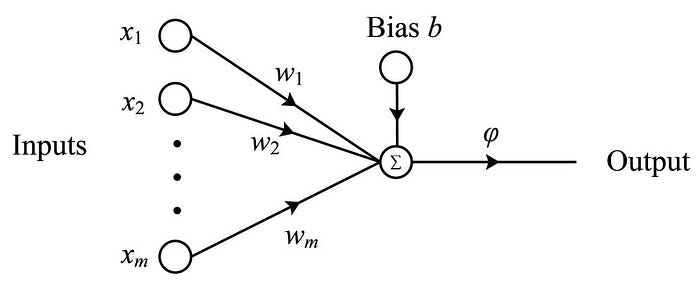
Perceptron (Image source: https://www.researchgate.net/publication/327392288_A_Quantum_Model_for_Multilayer_Perceptron)
权重可以帮助我们分配区分主要的输入内容和其余内容。例如判断一个人是否能获得贷款,他的收入证明输入会比他的姓名资料有更高的权重。偏置的作用是,在相同给定输入的情况下,在输入中添加或减去一个常数值,让不同的感知器会有不同的输出,然后这个总输出会传递给激活函数。激活函数的工作是:将输入映射到输出。激活函数有很多种,适应不同的工作情况。
本质上,这一个感知器也可以看作是一个 单层神经网络。当我们堆叠感知器的数量,并增加层数,就得到了一个深度神经网络。训练数据可以调整网络中每个感知器的参数,例如权重,偏置。接受输入数据的层被称为输入层,提供输出内容的层为输出层。中间的所有层为隐藏层。
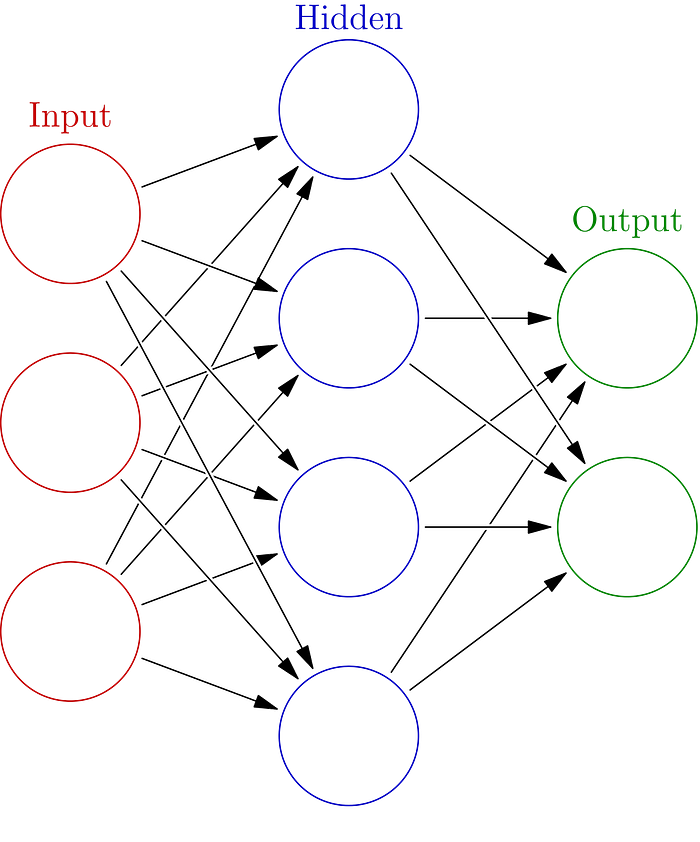
Neural Network (Image source: https://en.wikipedia.org/wiki/Artificial_neural_network)
回到循环神经网络,感知器的输入取决于特定时间的输入,由于是神经网络的构建块,所以神经网络的输出也取决于特定的时间输入。
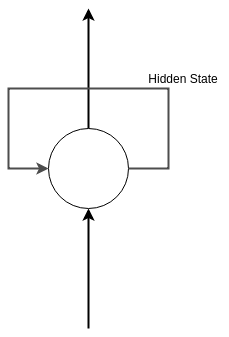
Recurrent Neural Network
当前状态的输入在下一个状态期间内再次反馈给隐藏层。这样,网络就可以知道先前状态发生了什么,或最后一个输入何时通过网络。又因为前一个状态也有关于之前状态的信息,所以这个输入一定程度上代表了完整的输入历史。
Step 2: TensorFlow.js和Magenta.js
Magenta是Google的一个开放项目,专注于在音乐和艺术领域使用神经网络。借助于TensorFlow来实现机器学习,可以通过Javascript来开发模型,在浏览器中训练并使用。
首先创建一个index.html和style.css:
1 |
|
自定义一些css样式,在之后神经网络输出的音乐添加样式,还引用了jQuery的loadash整理代码,tone.js播放音调,再通过magenta.js生成音乐。
1 | body { |
Step 3: 配置Tone.js
首先,创建一个卷积器,来创建mix。将wet值设置为0.3,是指将30%应用在音调上。
1 | let reverb = new Tone.Convolver('assets/small-drum-room.wav').toMaster(); |
然后创建鼓机的各个组件。
1 | let drumKit = [ |
为每一个声音连接到音频,创建Panner平移,产生立体声效果。
Step 4: 配置Magenta.js
在这里我们通过神经网络创建种子模式,然后创建旋律音乐。在我们开始使用神经网络之前,我们需要设置一些基础的方法,将音乐notes转化为可以被理解的序列。同样的,将返回的序列转化为tone.js可以播放后的模型。
为每一个tone的MIDI值创建映射关系。MIDI(Musical Instrument Digital Interface)是一个多设备处理音乐交流的协议。Magenta就是设计成这样的方式,让额外的设备可以更简单地直接播放。
一个机器学习的模型在输入范围被定义之后,可以表现得最佳。因为我们创建了一个映射关系,从MIDI对应到工作的模型。使用下面的值可以创建这个映射:
1 | const midiDrums = [36, 38, 42, 46, 41, 43, 45, 49, 51]; |
然后设置希望的参数,控制生成的强度:
1 | const temperature = 1.0; |
将notes转化为序列,我们使用下面的这个函数:
1 | function fromNoteSequence(seq, patternLength) { |
它包含了两个输入,notes的序列还有模式长度。Loadash被用于创建一个长度列表,被patternLength定义组成的空列表,可以在下一步被填充。杜立德notes可以被迭代多次,再重新写入,通过使用已经定义的reverseMidiMapping。
模型的输出现在可以被转化成序列,可以被用在鼓机里面播放的序列。通过下面的函数,将pattern序列转化为可以理解的note序列:
1 | function toNoteSequence(pattern) { |
这里是一些被定义的属性细节的解释:
ticksPerQuarter: ticks是MIDI开始的单元事件。
totalTime: 序列的长度已经在notes属性中提供了,这个长度是测量序列化的steps。
timeSignatures: 这个定义的时间签名用在音乐标注上。
tempos: 定义了被使用在tone sequence的temps,提供qpm代表每分钟的notes。
notes: 这个代表了notes中每个音的音高和持续时间。
当我们有了pattern序列之后,我们应该找到一个方法来播放它。我们会使用到创建的鼓机来播放。通过下面的方法获取pattern然后使用Tone.js来播放:
1 | function playPattern(pattern) { |
Tone.Sequence被用来完成这一步。它包含了3个输入:
callback: 这个方法可以唤回每个事件
event: 这个序列中的独立事件。我们映射单个pattern作为一个鼓组件的对象播放drum和stepId的序列。
subdivision: 在事件Tone.context.resume的戏份,开始音频内容需要连接浏览器提供的音频接口。
Tone.Transport: 确保音乐与浏览器的的时间序列保持一致。sequence.start最后完成设置。
通过这些你已经可以使用model来创建音乐了。在我们开始使用模型之前,我们可以看一看note pattern是什么样的。一个具体的pattern在pattern sequence是一个数组,从0-8序列,由9个鼓机组件组成。所以一个pattern[0, 2, 4]可以是播放Kick,Hi-hat closed 和 Tom low。
我们可以使用一个种子pattern,然后我们的模型会由此发散。使用下面的种子模型:
1 | var seedPattern = [ |
使用下面的片段定义函数,创建种子pattern然后创建pattern长度patternLength这个之前设置为32;
1 | let drumRnn = new |
我们首先开始加载DrumRNN模型,然后初始化它。我们然后创建函数使用这个模型,然后使用种子pattern来创建一个新的pattern,使用continueSequence方法。然后我们播放这个note序列,转化它到可以被鼓机播放的序列。我们已经链化displayPattern到可以被视觉化,然后通过playPattern方法来播放pattern。
添加可视化
接下来我们要为pattern创建可视化。现代的浏览器,例如Chrome需要用户在与页面互动之前,提供许可。这其实是一个可用性的功能。你可能不喜欢打开一个也没得时候就自动播放奇怪的音乐。我们会在HTML中添加一个播放按钮,添加onclick属性。这个方法参考了createAndPlayPattern我们在之前创建种子pattern的时候使用上了。我们不希望这个按钮在播放一次之后还可以继续访问,所以我们修改了createAndPlayPatternpattern来接受点击事件,然后删除页面的元素:
1 | function createAndPlayPattern(e) { |
最后添加displayPattern方法来可视化我们的pattern。在下面的方法中写入:
1 | function displayPattern(patterns) { |
它获取了pattern然后在页面上创建了多个<span>。每一个span对应鼓机里的组件,如果被激活或者播放他会是高亮的。同样的种子pattern也被高亮,很容易察觉到模型生成了什么。
结论
Recurrent neural networks提供了一个机器输入的机制。这让RNN能够非常好的预测音乐,因为音乐是声调的序列,而且互相依赖。Magenta是一个好的起点来进行这样的工作。
About this Post
This post is written by Siqi Shu, licensed under CC BY-NC 4.0.