在这一篇中集中学习poseNet的方法和使用示例。
PoseNet是一个实时分析人体姿势的机器学习模型。PoseNet可以识别单个和多个姿势,但是其中一个版本只能检测图像或视频中的一个人,另一个版本可以检测到多人。
PoseNet模型最早由Dan Oved迁移到Tensorflow.js中,你可以在这篇文章中学习更多:Real-time Human Pose Estimation in the Browser with TensorFlow.js
QuickStart
1 | const video = document.getElementById('video'); |
Usage
我们有几种对ml5.poseNet初始化的方法。
1 | // Initialize with video, type and callback 初始化:视频,类型,回调函数 |
video:可选的,用于HTMLVideoElement输入。
Type:可选的,当我们要选择是single还是multiple时,更改detectionType。默认为multiple.
Callback:可选的,加载模型是时的回调函数。
**Options: **可选的,包含影响posenet模型精度和结果属性的对象。
1 | { |
Properties
.net
PoseNet模型
.video
可选的添加视频
.architecture
模型的架构
.detectionType
识别类型
.imageScaleFactor
图片比例因子
.outputStride
可以是8,16,32,它指定了poseNet模型的输出步幅,数值越小,输出分辨率越高,精度越高,但速度更慢,牺牲准确性。
.flipHorizontal
布尔值,是否反转图像。
.scoreThreshold
临界值会返回一个值,在0~1之间,默认为0.5
.maxPoseDetections
最大的检测数,默认为5
.multiplier
可以是1.01, 1.0, 0.75,0.5之一。它是所有卷积操作的浮点乘数。数值越大,层的size越大,模型精度越高,速度更慢。
.inputResolution
可以是161,193,257,289,321,353,385,417,449,481,513,801之一,默认值为257.指定了图像在输入到PoseNet模型之前的大小,数值越大,精度越高,速度更慢。
.quantBytes
参数控制权重的字节。
.nmsRadius
如果两个部分的距离小于nmsRadius像素,则会互相抑制,默认为20.
Methods
.on(‘pose’, …)
事件监听,返回pose被检测的结果,你可以和
.singlePose()或.multiPose()一起使用,如果你传递了一个video给构造器。
1 | poseNet.on('pose', callback); |
Callback: 必要的,一个回调函数可以在检测到pose的时候处理结果,例如:
1
2
3
4poseNet.on('pose', (results)=> {
// do something with the results
console.log(results);
});Array:返回一个对象的数组。
。singlePose()
提供一个数字,然后会产生magicSparkles
1 | poseNet.singlePose(?input); |
input: 可选的,一个HTML视频或者图片元素,一个p5的图片或者是视频元素,如果没有输入提供,默认使用的是构造器的视频。
Array:返回一个对象数组。一个例子可以是:
1
2
3
4
5
6
7
8
9
10
11[
{
pose: {
keypoints: [{ position: { x, y }, score, part }, ...],
leftAngle: { x, y, confidence },
leftEar: { x, y, confidence },
leftElbow: { x, y, confidence },
...
},
},
];
.multiPose()
同样,产生magicSparkles
1 | poseNet.multiPose(?input); |
input: 可选的,一个HTML视频或者图片元素。如果没有输入提供,默认使用的是构造器的视频。
Array: 返回一个对象数组,示例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20[
{
pose: {
keypoints: [{ position: { x, y }, score, part }, ...],
leftAngle: { x, y, confidence },
leftEar: { x, y, confidence },
leftElbow: { x, y, confidence },
...
},
},
{
pose: {
keypoints: [{ position: { x, y }, score, part }, ...],
leftAngle: { x, y, confidence },
leftEar: { x, y, confidence },
leftElbow: { x, y, confidence },
...
},
},
];
PoseNet run in the browser with TensorFlow.js
这是一些关于PoseNet迁移到TensorFlow.js的笔记,关于更多的内容,可以查看:Real-time Human Pose Estimation in the Browser with TensorFlow.js
PoseNet可以用来评估单个或是多个的pose,我们的样本可以是视频,也可以是图像,但是这有两个版本,单人pose检测更快,更简单。
更深入的,pose检测发生在两个阶段:
1.一个RGB图像输入,通过卷积神经网络。
2.使用SinglePose或MultiPose解码算法,解码pose,pose的置信分数,以及pose的关键置信分数,你可以在model的输出找到。
那这些关键词意味着什么?让我们重新梳理一下:
**Pose – **在最高级别,PoseNet会返回一个pose对象,包含了每一个检测姿势的关键点和置信分数。

**Pose confidence score – **这个决定了整体评估的置信度,它的范围从0.0到1.0,可以被用于隐藏那些不够明显的pose。
**Keypoint – **包含一个人姿势评估的部分,例如鼻子,左耳,左膝,右脚等等,除了关键点的位置外,也会包含每个关键点的信心分数。PoseNet当前可以检测17个关键点,例如下图:
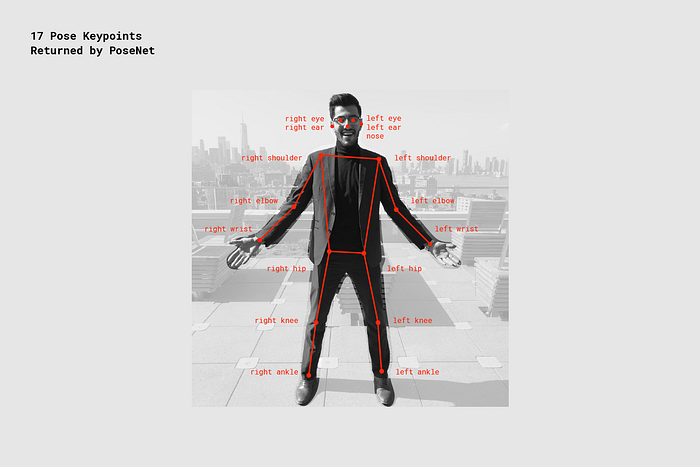
**Keypoint Confidence Score – **7这个评估了关键点的置信分数,范围在0.0~1.0之间,他可以用于隐藏不够明显的关键点。
**Keypoint Position – **在输入图像中检测关键点的2Dx和y坐标。
第一部分:倒入TensorFlow.js和PoseNet库
许多工作都可以将抽象模型的复杂性并将功能封装到易于使用的方法。我们可以回顾一下设置PoseNet的基础知识。
首先,可以通过npm安装:
1 | npm install @ tensorflow-models/posenet |
然后使用es6模块导入:
1 | import * as posenet from '@tensorflow-models/posenet'; |
或者在页面中引用:
1 | <html> |
第二部分:单人Pose检测

单人检测模型是一个更加简单和快速的检测算法。理想的使用情况是只有一个人在输入的图像或视频中。不足之处是如果图片中出现了两个人,识别的姿势会是两个人组合起来的样子。
让我们来看单人检测算法的输入内容:
**Input image element – **一个html元素可以包含一个图像和预测的pose。但是输入的图像和视频元素需要是方形的。
**Image scale factor – **一个在0.2~1之间的数字,默认是0.5,可以通过网络在feed之前进行缩放。我们可以通过调低这一属性,来提升图像的处理速度,但是会损失一部分的准确性。
**Flip horizontal – **默认为false,如果图片需要左右翻转,你可以设置这一属性。
**Output stride – **必须是32,16,或8.默认为16.这个参数会影响神经网络中层的高和宽。更深入地理解,它会影响pose识别的准确度和速度。更低的值会有更高的准确度,但是速度会更低,高值会加速,但是准确度下降。查看输出效果的最好方法,是从这个Single-pose estimation demo查看。
让我们来回顾一下single-pose检测算法的output:
- 会包含有17个关键点的数组,以及置信分数。
- 每个关键点会包含节点的位置信息和节点的置信分数。所有的关键点都会有在输入图片中的x和y坐标。可以直接映射到图像中。
下面这个简短的代码块展示了single-pose检测算法:
1 | const imageScaleFactor = 0.50; |
一个输出pose的例子看起来是这样:
1 | { |
第二部分:Multi-person Pose Estimation

多人pose检测算法可以检测在一张图片中的多人姿势。它会更加复杂也处理起来更缓慢。即使是在多人图像中,它也更不容易识别出错误的姿势,换句话说,即使是检测单人pose,这个算法也更可取。
进一步而言,这个算法另一个亮点是,他不会受到输入图像中人数影响。无论是15个人或5个人,计算的时间是一样的。
让我们来看看inputs的内容:
**Input image element – **和单人检测相同
**Image scale factor –**和单人检测相同
**Flip horizontal – **和单人检测相同
**Output stride – **和单人检测相同
**Maximum pose detections – **一个整数,默认为5。最大的姿势检测数量。
**Pose confidence score threshold – **0.0到1.0,默认为0.5。控制最小的置信分数返回值。
**Non-maximum suppression(NMS) radius – **以像素为单位的一个数字。这个控制了姿势之间的最小距离。默认值为20,这在大多数情况下使用。在准确度不够的时候我们可以调整这个数值。
你可以在这个Multi-pose estimation demo查看具体的实现效果。
让我们来回顾一下输出:
- promise解决了poses的数组。
- 每个pose都会包含相同的信息,和单人pose检测算法一样。
下面简短的代码块显示了多人检测是如何实现的:
1 | const imageScaleFactor = 0.50; |
输出数组的例子看起来是这样:
1 | // array of poses/persons |
更进一步的技术探索
在这一部分,我们会深入理解单人姿势检测的技术细节,这个过程可能是这样的:
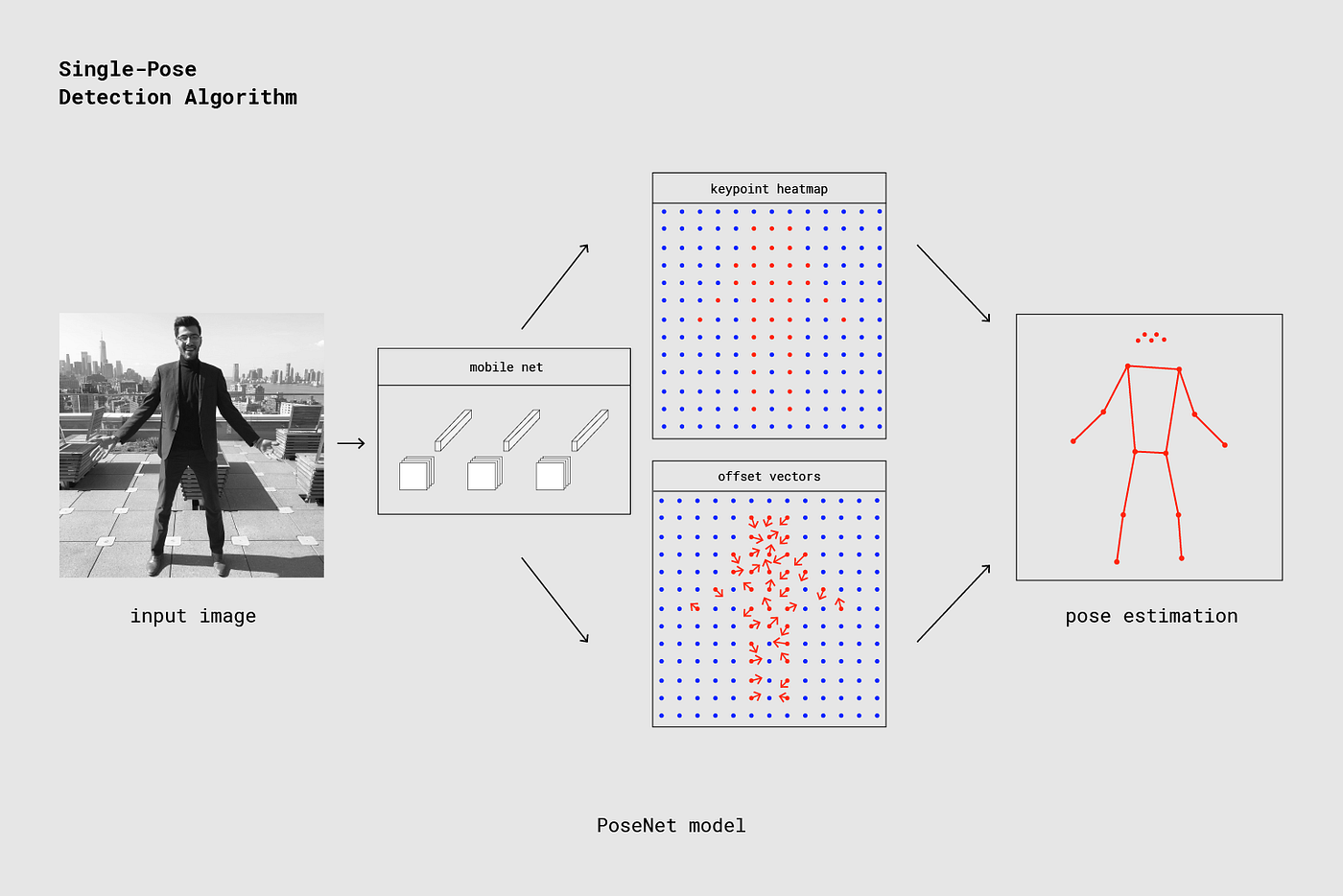
一个重要的细节是,研究员同时训练了PoseNet的ResNet和MobileNet模型。但是ResNet模型有更高的准确度,但是更大且更多的层会让页面的加载时间不理想,特别是在实时应用的时候。我们通过MobileNet模型驱动,因为它是为移动设备而设计的。
重新查看单人pose检测算法
Processing Model Inputs: Output Strides的解释
首先我们需要了解获取PoseNet模型的输出,通过讨论output strides。
PoseNet是图像不变的,这意味着它可以在原始图像上预测姿势,而不需要考虑是否缩放。所以我们可以设置output strides,牺牲一部分的性能配置,提升PoseNet的准确性。
Output stride决定了我们输出缩放了多少,相较于输入图像的大小。它会影响层的大小还有模型的输出。更高的output stride,会有更低的图层解析度在网络和outputs中,相应的影响准确度。
output stride可以有8,16,32。换句话说,output stride为32会有最快速的表现但是最低的准确定,值为8的状况会有最高的准确度但是最低的速度,所以我们推荐使用16.

当output stride设置为8或者16,层中的输入步幅降低,来创造更高的输出分辨率。
Model Outputs: 热力图和偏移向量
当PoseNet处理图片,实际上是返回了一个热力图,以及偏移向量,可以背解码同找到pose存在的更高置信区。下图是一个演示每个pose关键点是如何关联到热力张量和偏移向量张量。
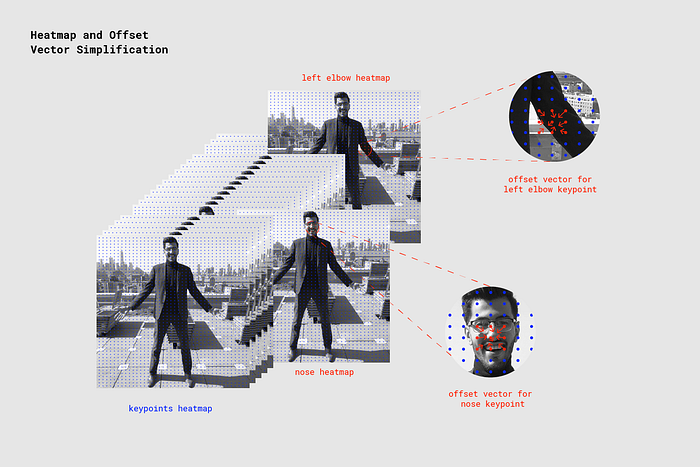
这些输出都是3D张量,我们可以通过分辨率来取代。分辨率由输入图片的大小以及output stride一起决定的,通过下列的公式:
1 | Resolution = ((InputImageSize - 1) / OutputStride) + 1 |
热力图
每一张热力图是3D张量的大小,分辨率x分辨率x17,因为有17个PoseNet可以识别的关键点。例如,一个图片大小为225,output stride是16,那么热力图会是15x15x17.每一个切片对应到具体的关键点。每个坐标都有一个置信分数。关键点类型存在的位置。可以被认为是原有的图像被切分成了15x15的网格,热力图可以提供分类每个关键点存在网格是什么样。
偏移向量
每个便宜向量是3D张量,分辨率x分辨率x34,34是关键点数量的两倍,所以一张大小为225的图像,output stride为16,那么它会是15x15x34. 因热力图金丝关键点的位置,偏移向量对应热力图点的坐标,前17张包含了x坐标的向量,后17张则为y坐标。偏移向量的大小和原始图像相同。
从模型的输出来识别Pose
在图像从被投喂给模型之后,我们通过一系列的计算来检测pose。单人pose检测算法回返回pose的置信分数,包含了一个有关键点的数组,坐标,还有每个节点的分数。
为了的到关键点的pose:
1.sigmoid激活函数在热力图中去取得分数。
scores = heatmap.sigmoid()
2.argmax2d在关键节点置信分数去取得x和y的序列,和没部分的最高分数存在的坐标,这会是一个17x2的张量,热力图中最高分数的y和x序列。
heatmapPositions = scores.argmax(y,x)
3.offset vector从热力图中取回每个部分的x和y。一个17x2的张量。例如我们想的到一个序列为k的点的坐标:
offsetVector = [offsets.get(y, x, k), offset.get(y, x, 17+k)]
4.得到keypoint,热力图x和y的每个部分叠加通过output stride,当添加他们对应偏移向量,会和原始图像有相同的大小。
keypointPositions = heatmapPositions * outputStride + offsetVectors
5.最后,keypoint confidence score是热力图坐标的置信分数。pose的置信分数就是关键点分数的综合。
About this Post
This post is written by Siqi Shu, licensed under CC BY-NC 4.0.