Order Matters & Distance Matters
Our previous represenatations have only considered word presence and frequency:
Jon hit the cricket bat
The cricket bat hit Jon
These two sentences mean different things, but would look the same.
Where wods are in a sentence matters:
Jon, despite being a mild mannered and unremarkable man normally unlikely to get angry, flew into a rage.
The word rage relates to Jon but is far away from it in the sentence.
N-grams
We have looked at n-grams as tokens as ways of capturing links between words; however, these can make your vocabulary large, and your input sparse.
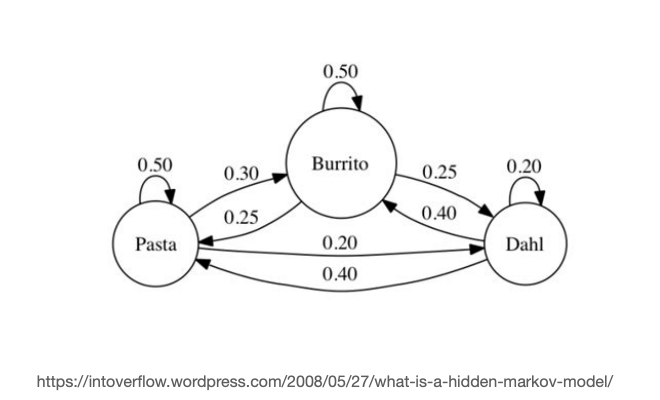
Markov Models
We have also looked at Markov Models as a way of modelling sequences (by looking at the probability of transitioning from state <-> state)
Before we kick into the more complex set ups, its important to remember these things are essentially the same as the straight forward neural networks we’ve seen before.
Different layers pass information between each other, being changed by weights. The aim is to get the best version of these weights, and we do this by iteratively nudging them towards better performances.
Sliding Windows
How can we capture spatial information about text input?
We take a filter and slide it over windows of time series data; Originally designed for image tasks.
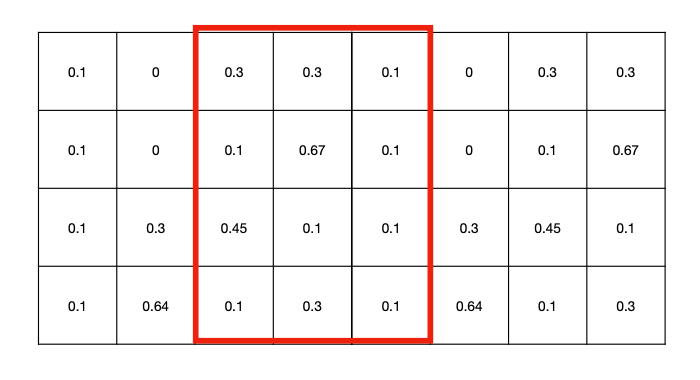
The network learns filters that activate when it detects some specific type of feature at some spatial position in the input.
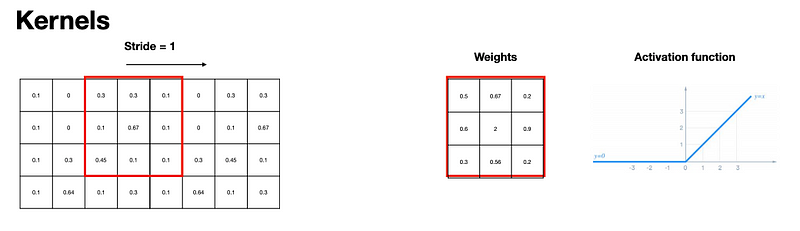
The filter we slide is across is known as a kernel.
The amount we move it by is known as the stride.
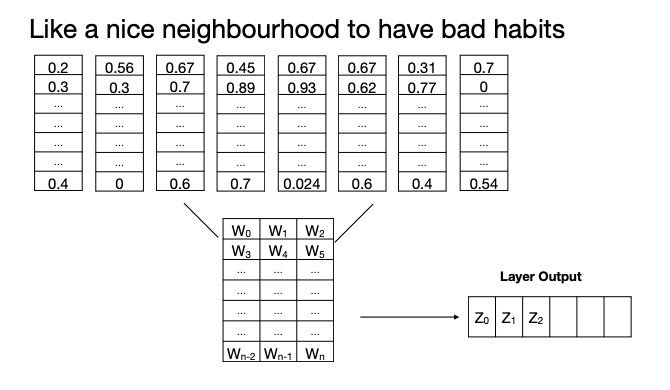
Each filter has a set of weights, and an activation function.
Multiply input by weights element-wise.
Sum and put through activation function (often ReLU), move and continue.
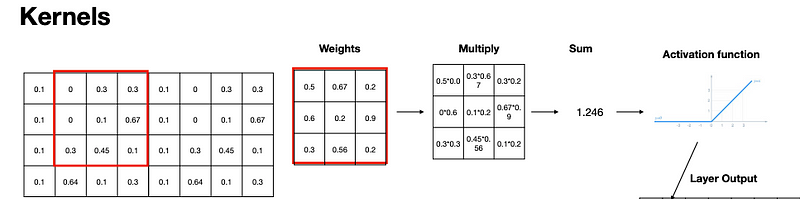
z_0 = max(sum(x8w), 0).
Padding
You are going to miss some numbers at the edge. We can stop this by padding, better than missing data.
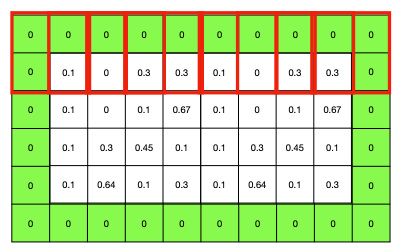
A Text Dataset - Supervised learning needs pairs
We take sentences from books and guess the genre, out of 6 possible.
This is one input example e.g. one document.

We only care about one dimension with Word Vector Inputs(this is 3x1).

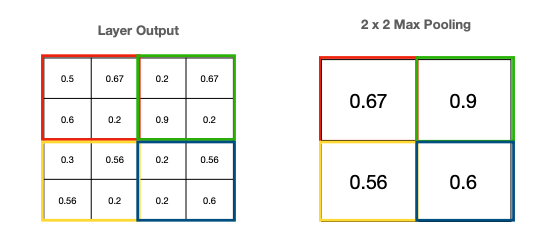
Pooling
We actually have multiple filter/kernels in each layer.
We use pooling as a dimensionality reduction and to learn higher order features.
We take subsections and amalgamate by either max or average.
Dropout
We sometimes also add in a dropout layer. This 0’s a certain percentage of random units every pass.
Helps prevent overfitting. Doesn’t happen when doing inference with the trained model.
CNN Structure
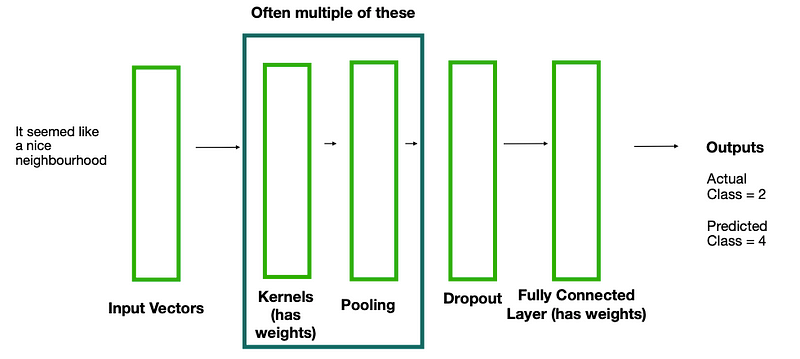
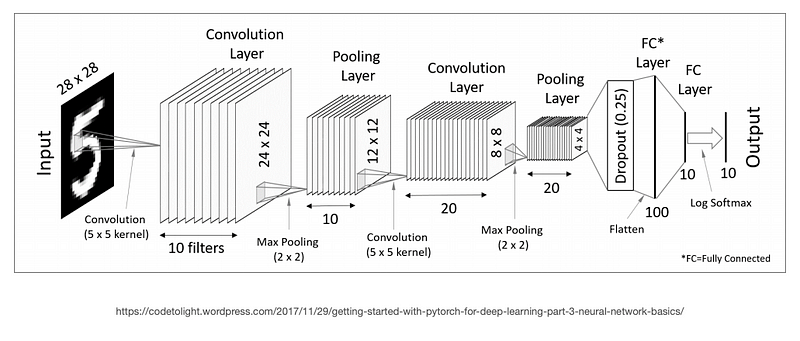
We update the weights in the same manner as normal feed forward networks.
Using backpropagation and some optimizer.
Using a loss function appropriate to the task e.g. for 2 class classification its binary cross entropy loss.
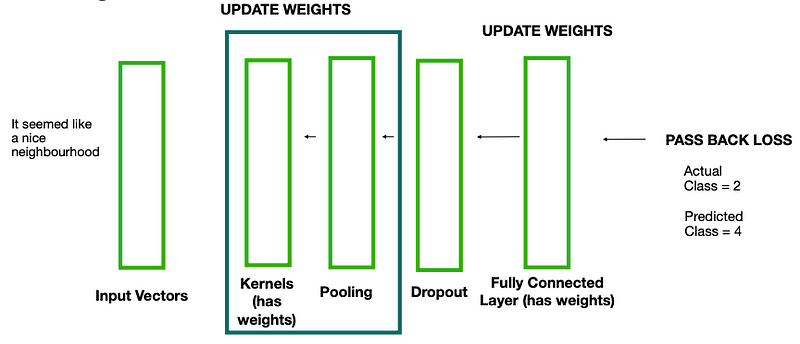
Feedback loops
RNNs are more similar to the feedforward networks. Built up of interconnected neurons.
A traditional neuron just sums up inputs then outputs.
We add in each token one by one but the information is lost.
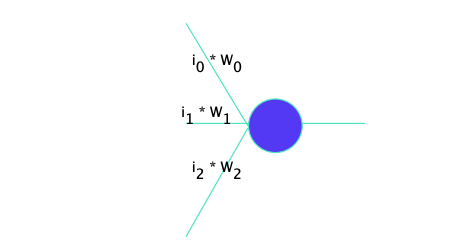

Each example is still one set of word embeddings and one label.
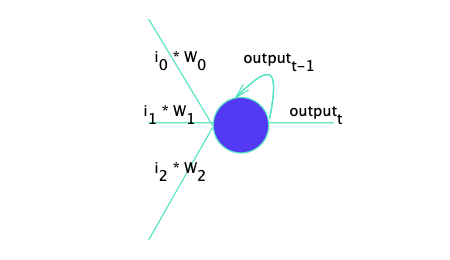
However, each token is fed in 1 by 1, with the current step referred to as t.
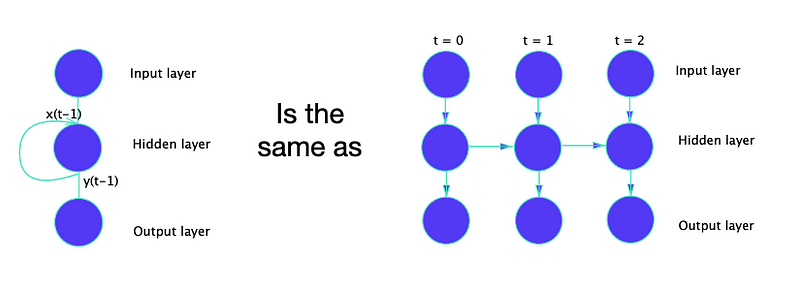
For our classification task, we only care about the last output.
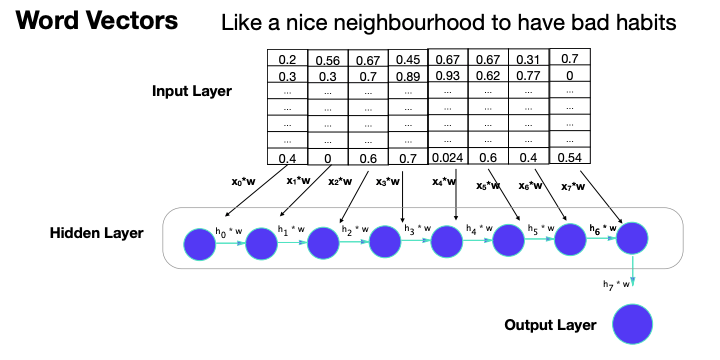
Same as with the normal neural network we use back propagation to pass the loss back along the network and update the weights.
Its slightly more complicated with the recurrent layers and it referred to as back propagation through time.
Its a classification task, so we are looking for 100% accuracy in the best case.
Other Types of RNN Neuron
There have been improvements to RNN neurons over the years.
They remember, but also forget what’s not important
- GRU
- LSTM
We’ve been making classifiers so our dataset has consisted of pairs of input sentences and labels.
This means we can give it new sentences and it will guess the label.
About this Post
This post is written by Siqi Shu, licensed under CC BY-NC 4.0.