Motivation for sequential models

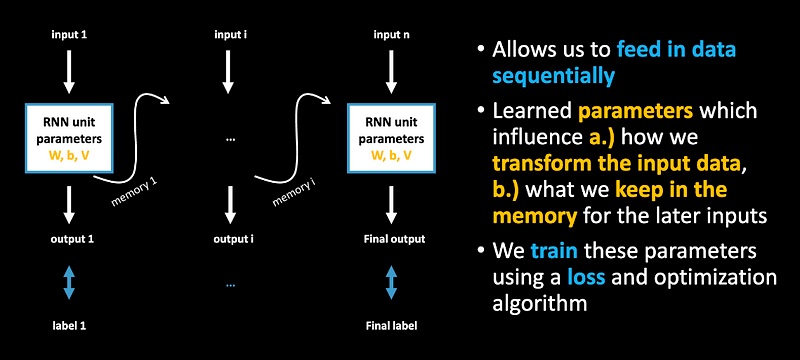
In this essay, closer look into the unit design, how can this be used for data generation.
Example 1: Music Generation
Example of a possible model with two layers of LSTMs. We prepared our dataset as sequences of 40 frames predicting the next 1 frame (“many to one”), the model learns the transformation of x-> y.

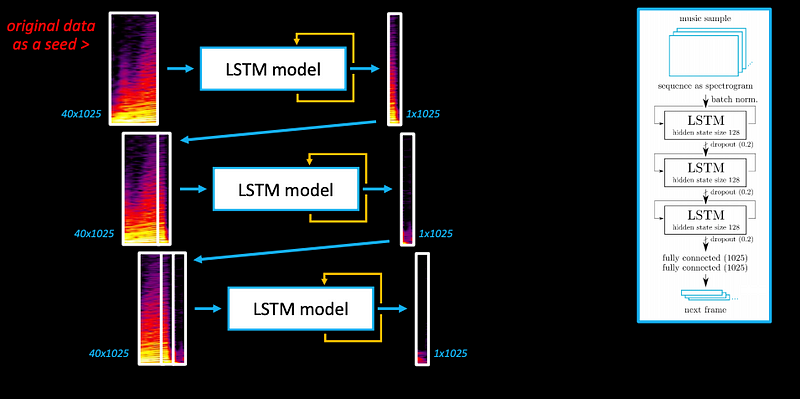
Check the generated music sample: https://soundcloud.com/previtus/ml-jazz-meanderings-ml-generated-sounds-1/s-DCZbx
Example 2: Stock Market
There are similarities between the “next value prediction” task and a generative task (given the way how we use these models).
Remember this when you are using them for your creative projects -> we might want irregularities, model breaking, training on multiple sources…etc.

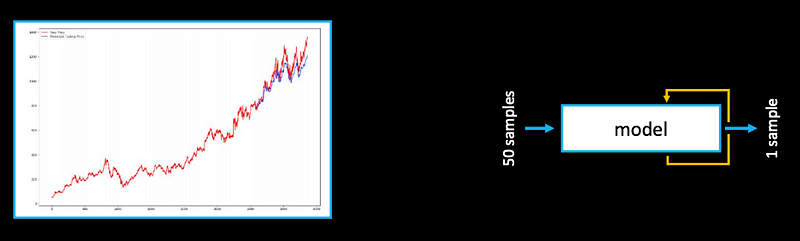
The less common, even worse outcome.
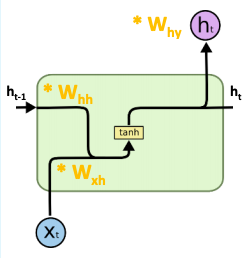
Vanilla RNN
As math formulas:
ℎ𝑡 = 𝑡𝑎𝑛ℎ(𝑊𝑥ℎ ∗ 𝑥𝑡 + 𝑊ℎℎ ∗ ℎ𝑡−1)
y𝑡 = 𝑊𝑦ℎ ∗ℎ𝑡
1 | class RNN: |
Forgetting information
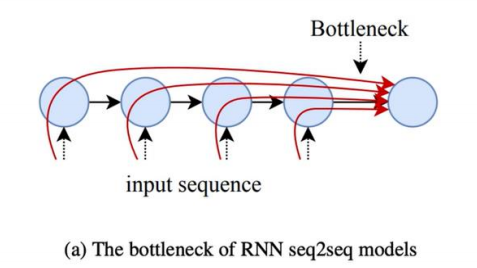
Which has one weakness -ℎ𝑡 carries information to be stored in the memory and aloso for output…
Long Short Term Memory Unit (LSTM)
This will be a rough animation of data passing through LSTM. Kepp in mind that we do not really care about each detail at this point - rather we wwant to see why is it better at remembering long-term dependencies than the vanilla RNN…
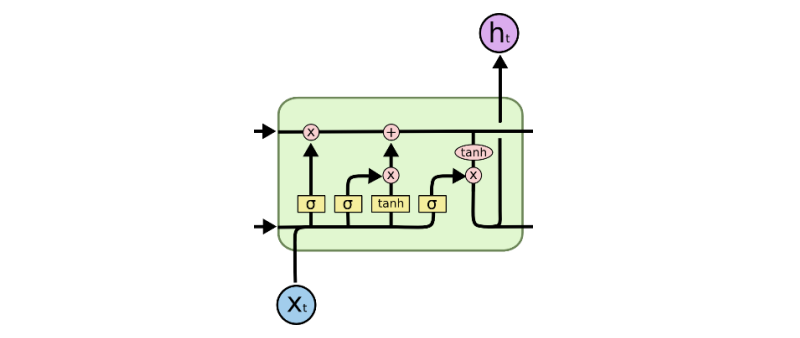
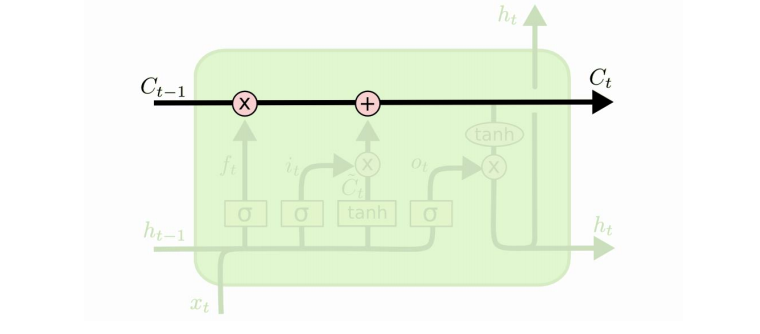
Main idea: independent channel to carry long-term memory.
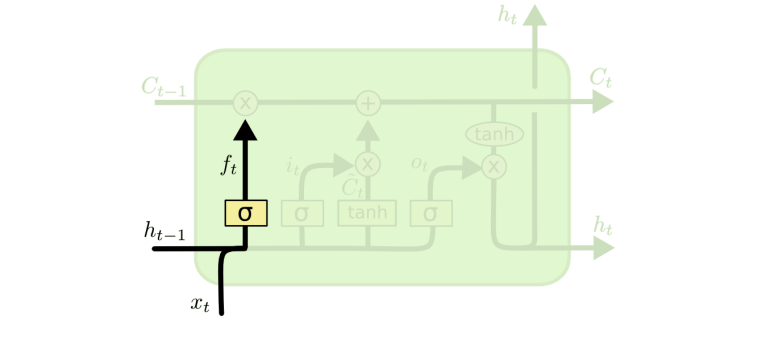
Forget gate influences what we delete from memory.
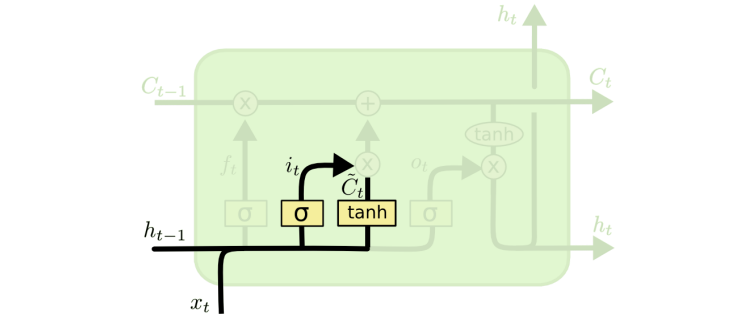
Input gate selects what to read from input.

Then we add it to the memory.

Output gate combines everything together.
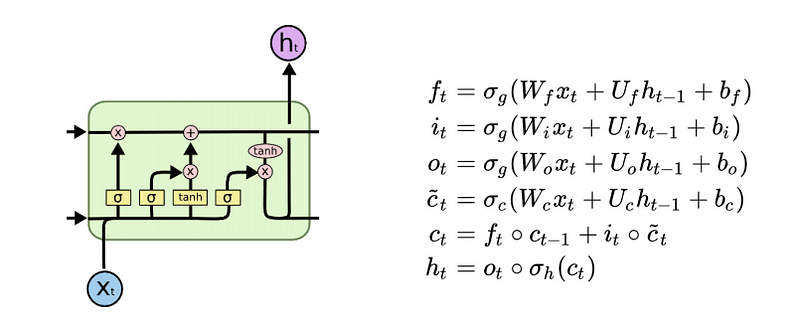
These operations are inlfuenced by learned parameters (W, U, b).
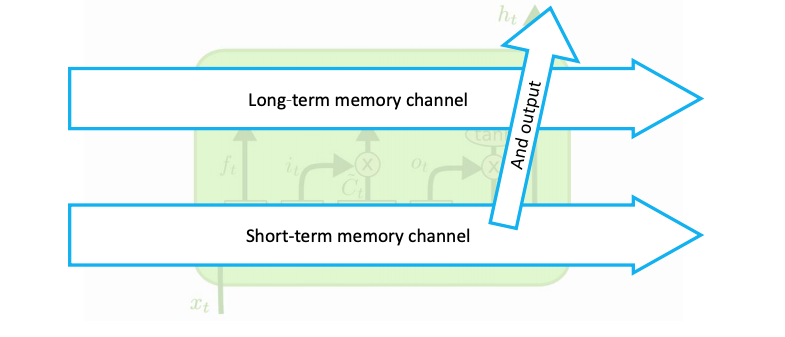
In addition to the basic RNN we have a special channel for long-term mem.
In-depth look: RNNs and LSTMs
Recurrent Neural Networks (RNN): Simpler unit design
Long-Short Term Memory (LSTM): More complex unit design, made to remember longer dependencies inside the data.
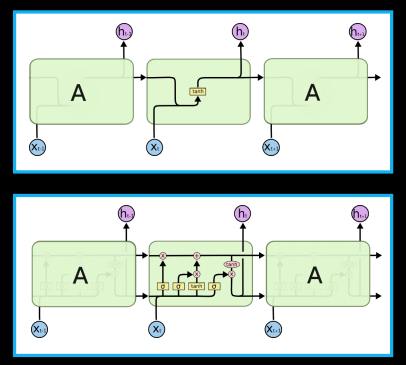
In code we set up the dimension of the data flowing through these models - that’s the size of the vectors h and c.
1 | from tensorflow.keras import layers |
Loss functions
We want to measure the distance between two vector (typically this is betwenn predictions and labels):

Cross-Entropy loss


About this Post
This post is written by Siqi Shu, licensed under CC BY-NC 4.0.