We have seen how different representations (beyond the raw form) of our media inputs can help us build more accurate classifiers, depending on the problems we are trying to solve.
For video input, we have looked at:
- MobileNet (good for objects)
- BodyPix (good for bodies)
For Audio:
- FFT, MFCCs, Musical Inputs
These preprocessing steps presented our data in a way that meant the learning algorithms had an easier job identifying the differences between each class.
Given just raw media data, our models have to learn about things in the world (bodies, objects, music) in order to learn the differences between our classes.
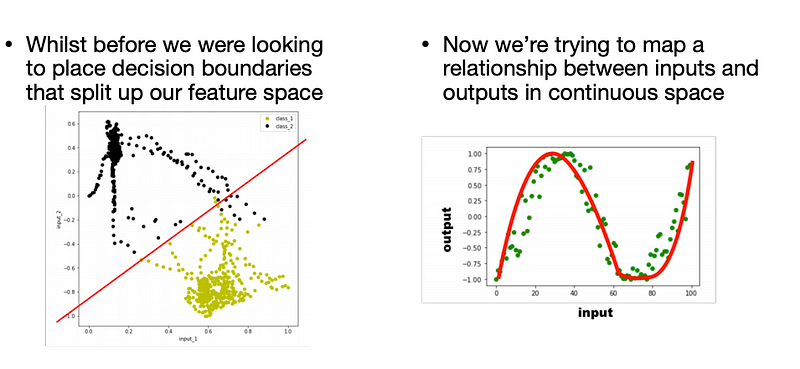
When we have 2 input features, we can look at our datasets as 2D plots. And we can see a classification problem as dividing up this plot.

Improving Classifications
This logic works when we have more input features, but its hard to visualise!
Each learning algorithm will have its own approach to dividing up the space, and the types of Decision Boundaries it is able to make.
Whilst some learning models can fit complex decision boundaries, the more our representation highlights the differences between classes, the easier it is to build a good model!
Complex models also often require more data. We can often achieve better representations of real time media data using time based features.
We can now use some maths to aggregate inputs over time:
- Smoothing / removing noise
- Finding rate and direction changes
- Finding amount of changes
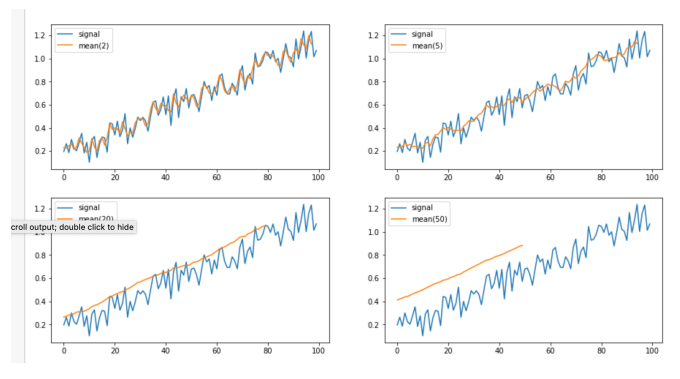
We take our array of existing inputs and each value becomes the average over the previous n values.

Window size effects smoothing.
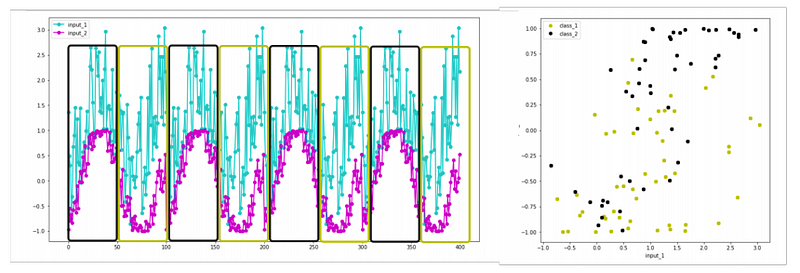
Using these two featuers, it is hard to separate the classes.
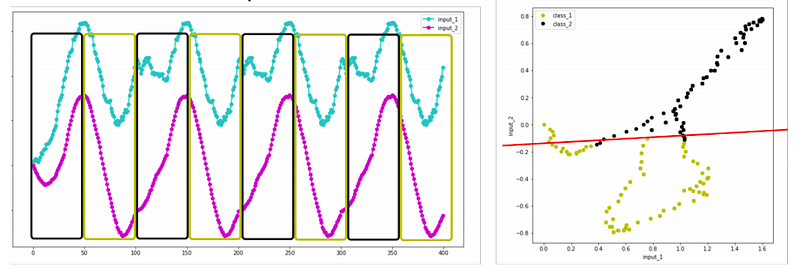
When we take a running average, it smooths out the noise and makes the classes much more separable.
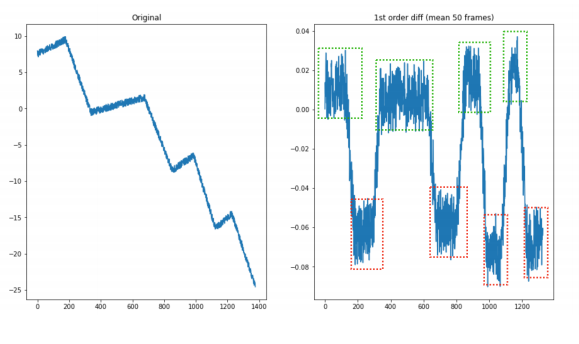
First order difference can tell us the rate of change:
at = a(t) - a(t-1)

Second order difference can tell us the rate of that change.
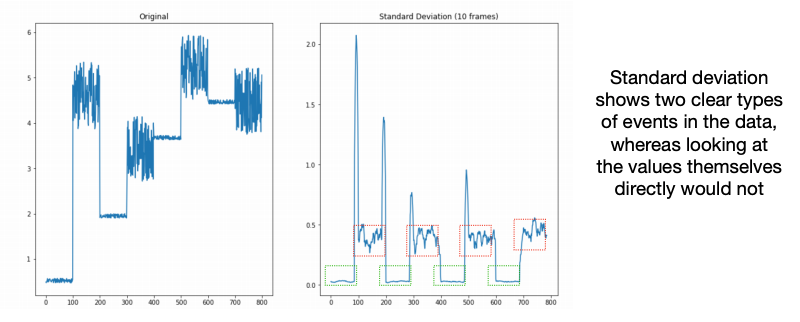
There are two clear groups here (different gestures/activities?) that we can see when measured with first order difference, which we would not get when just looking at values.
Variance
Standard deviation tells us how much variance there is in a window of data.
Variance is the mean distance from the mean of the group.

Standard deviation
Standard Deviation tells us how much variance there is in a window of data. Variance is the mean disstance from the mean of the group. Standard deviation is the square root of this.
This representation can highlight differences between classes that raw data would not.
Effect on Classification
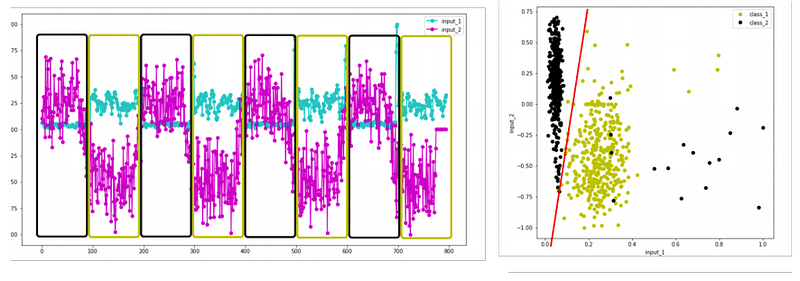
These two inputs do not allow to easily separate the two classes.

Taking the first order difference of one input, and the standard deviation of another makes the differences between each class much clearer.
Smoothing them with a running average makes it even clearer.

Whilst some learning models can fit complex decision boudnaries, the more our representation highlights the differences between classes, the easier it is to build a good model.
Complex models also often require more data.
We can often achieve better representations of real time media data using time based features. In situations where the exact values may not match between examples in a class, but the way they change over time might.
We can add features to our datasets using the Learning.js library:
1 | learner.setFeatures([ |
Demo: https://mimicproject.com/code/ac8f243b-4c35-4004-d32e-b94b1f6d1eae
Class 1 = small movements, Class 2 = Big movements
We can see how using standard deviation allows us to model phenomena we could with just raw coordinates as we move towards classifying gestures rather than just poses.
Continuous Labels
Up until this point we have been tackling classification tasks, which means we have been identifying discrete classes.
The labels we store in our dataset, and the labels we apply to new data are discrete numbers.
However, we can also use models that can use continuous labels! This means we can provide a few examples mappings from inputs to outputs, and the model can learn to fill in the gaps.
Mappings for Music
Demo: https://mimicproject.com/code/2fdd8ba2-3cb8-1838-49a5-fe9cfe6650ed
This process can also allow you to find sounds in ways you could not before, and perform in ways you could not before.
This allows us to use the body as an input without manually programming lots of mappings.
And control lots of parameter at once (we only have two hands!).

About this Post
This post is written by Siqi Shu, licensed under CC BY-NC 4.0.